Tree-mendous Events
Fault trees are, fundamentally, backwards looking. They start from the premise of a failure having happened (or an attack succeeding if you're calling them attack trees).
Even if you're just using them on theoretical failures, they're about decomposing something that's happened.
Event trees are the flip side of that.
When to Use It
Like fault trees, event trees are best used when designing a system. Instead of going from a failure (or attack goal) and working backwards to a cause, we can take a failure and working forwards to understand consequences. We can also take normal operations and work forwards to discover potential failure modes.
If you're designing a system it's a way to discover which components are critical, and which can be worked around if a failure happens. Best used when you need something resilient, which is why it's often applied to safety-critical physical engineering systems.
How It Works
As with fault trees, we start with the 'root' event (yes, I know, we need better terminology). You can go from the 'root' downwards as with a fault tree, but often it's left to right, because apparently people doing this sort of work have never seen a tree in their lives.
Usually, but not always, event trees are binary at each stage, with questions running along the top (or side) representing the safeguards.
Unlike a fault tree we're less interested in finding dependencies than in working out likelihoods of each layer of safeguards failing, and so probability comes in more often than with fault or attack trees (it's still optional).
To keep things simple and relatable, I'm going to run through dinner.
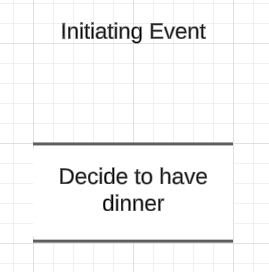
We start out with the initiating event, in this case that I've decided it's time to eat. Obviously that leads to a natural decision to be made, and subsequent events.
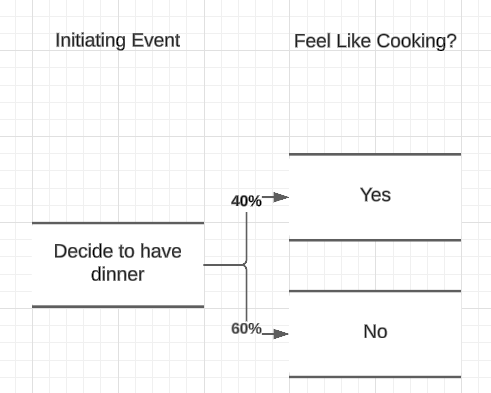
The next question is whether or not I feel like cooking, with probabilities assigned to each. I'm saying it's a Friday night after a long day of work, so the probabilities are non-typical, with only a 40% chance that I'm in the mood to rustle something up myself.

As you run through an event tree, some questions will only be relevant to certain branches. In these cases you can ignore those questions for non-relevant branches. As you can see, if I don't feel like cooking it's not relevant whether there are ingredients, because we're probably going for a takeaway.
To keep things simply, I'm not going to run through the full cooking recipe, so we've only got a couple of safeguards left.
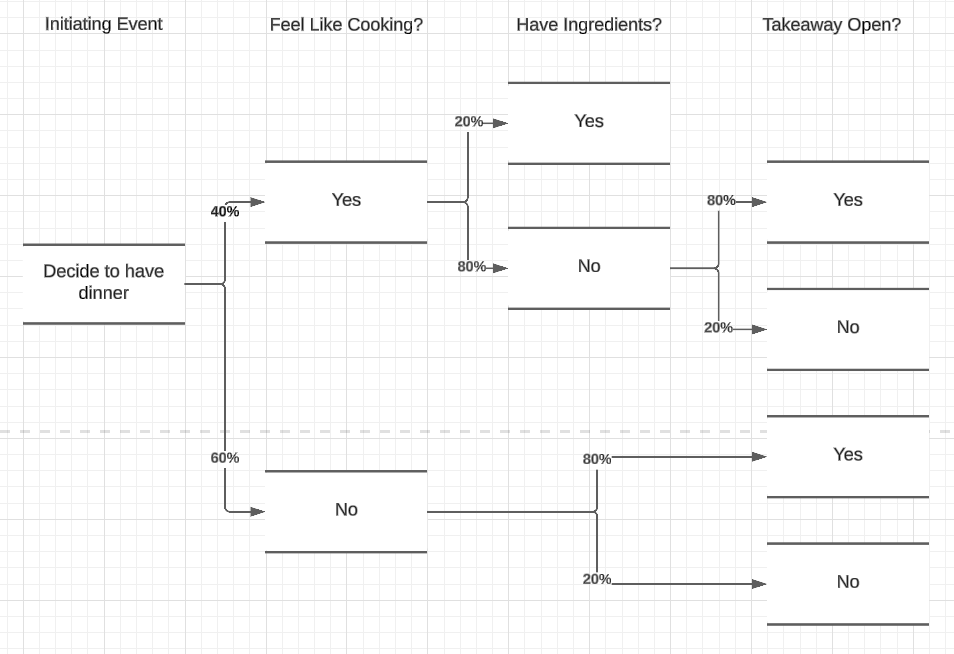
Note that while we could merge two paths here, knowing that the outcomes will be the same, we never converge paths in an event tree. This is because the probability and outcome of each path depends on all the previous questions.
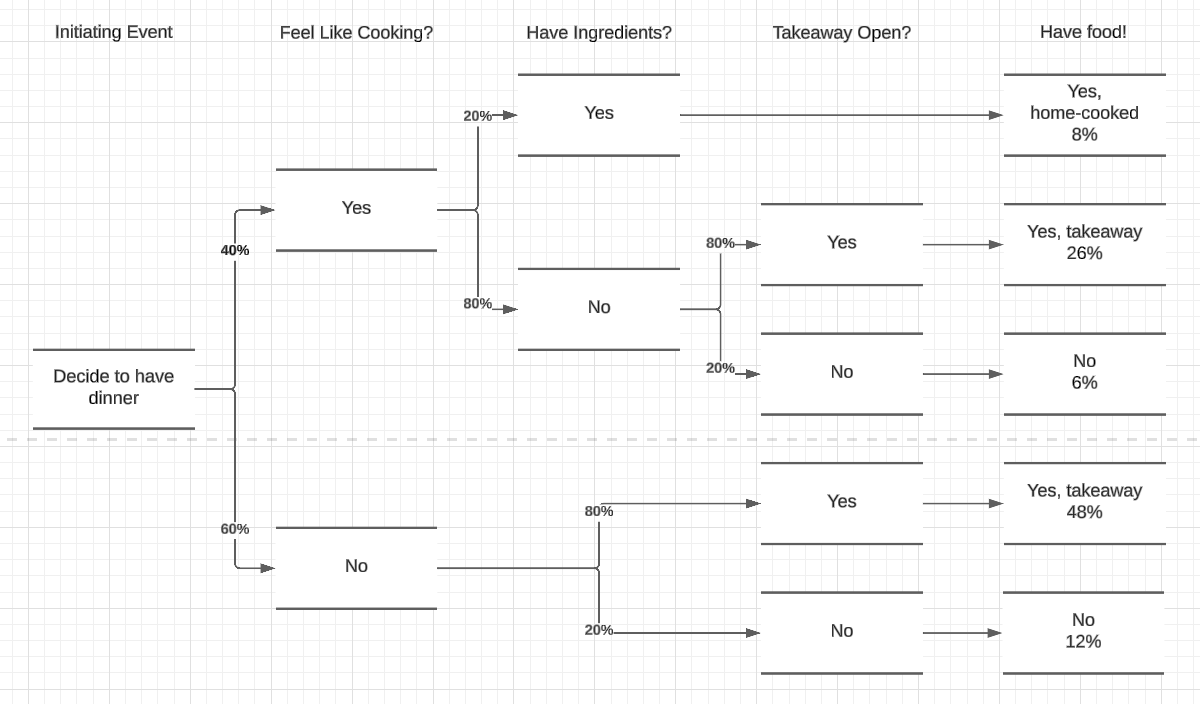
Finally we get to the results of the paths. There may be multiple routes to success, and we can work out the probability of success or failure overall using this approach. It also allows us to quickly spot which areas we could improve to change the changes of success - for example making sure groceries were available would make home-cooked food much more likely.