Faulty Attack Trees
There's an argument that fault trees and attack trees are different approaches.
I find fault (hah) with that argument. Ultimately, they're the same, just applied slightly differently.
Both are a straightforward method to either attempt to predict and prevent an undesirable outcome, or to diagnose one from the outcome to root causes to investigate (even though the root is the bottom/top of the tree - the terminology is just messed up).
When to Use It
Both fault and attack trees are most useful when designing a system, although they can both be used as diagnosis tools to work from a known outcome and try to establish causes. They are a low-effort tool, although metadata can be added to specialise them to all sorts of purposes such as adding probability factors, or costings.
Ideally any system will have multiple trees covering different undesirable outcomes, and this could easily be done in software (or on a very large whiteboard, or with a lot of post-its) to allow contributory factors to multiple outcomes to be easily pulled out.
How It Works
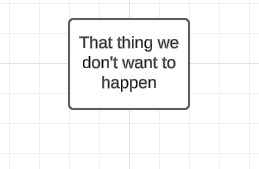
Both fault and attack trees start with an outcome as the 'root' (paradoxically often drawn at the top when using a whiteboard) of the tree. For attack trees, this will be the goal of the attackers while for fault trees this will be the undesired failure mode. Basically, it's a thing we don't want to happen.
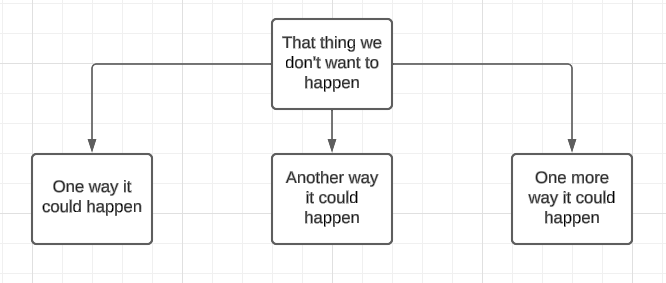
Steps 2 onwards are really about channelling your inner toddler. We think about what could cause the thing we don't want to happen to happen, and draw them below (or above if you want it to look more tree-like) the 'root'.
In step 3, you've guessed it, for each cause we think about what the prerequisites for that to happen are (why, why, why?) and add them to the tree.
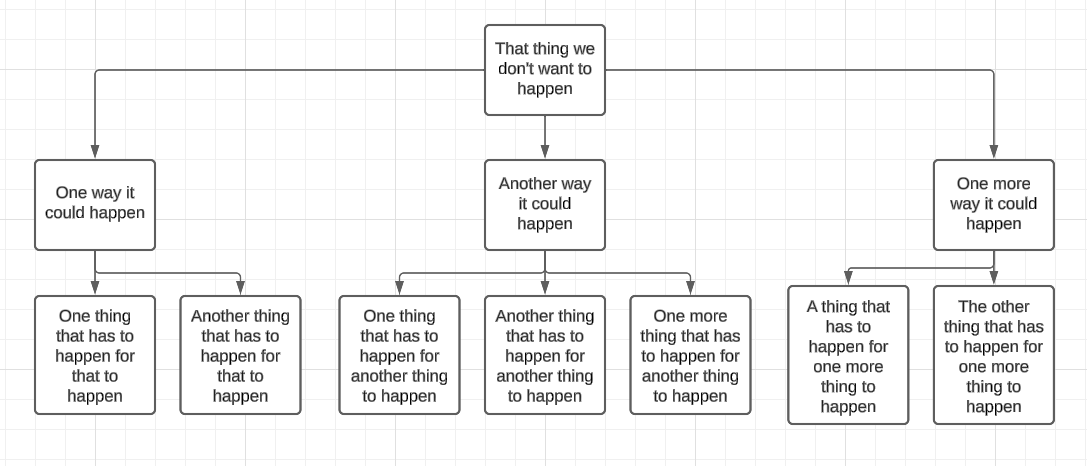
Then, repeat, drawing out dependencies as you go. It doesn't matter whether it's an attack, or a failure of a system, the approach is the same.
One of the hardest challenges with these approaches is knowing when to stop. My usual rule of thumb is that more than five levels is probably excessive (that's when the toddler gets annoying), but with more complex systems you may want to go deeper while with simpler ones you may want to stay at a higher level.
Teams are best for these, although an ideal would be to have an evolving forest of trees (stretching a metaphor) that can be added to and developed as time goes on.
The biggest use is that they highlight dependencies for the failure modes, allowing the system designer to block routes at any point through applying risk mitigation strategies to prevent the higher level failure.